Human evaluation usage (for project managers)
To initiate a human evaluation in Companion, the project manager can use the New Human Evaluation Job button in the Human Evaluation section of Companion.
For all Job Types, the project manager must:
be assigned Owner or Maintainer role in a Workspace.
know which evaluation job type will be used. See more information about Job Types.
provide a meaningful job name. This name is for internal use only and is not exposed to the evaluator(s).
know the language pairs to be evaluated.
know which scoring system will be used for the evaluation, and that scoring system must be available in Companion
have data prepared in a specific format based on the human evaluation job type – one document per language pair. Also, the file must be named according to the HEVAL Input File Naming Convention.
know how many evaluators are required for the job.
know which resources (evaluators) should be assigned to the job for each language.
know the project end date.
Following sub-chapters describes how to create job for particular type and explains required fields as well as the input file format:
- New Quality Assessment (QA) job
- New Quality Assessment With annotation (QAA) Job
- New Quality Assessment With Annotation on Paragraphs (QAP) Job
- New Comparative Assessment (CA) Job
- New Comparative Assessment With Annotation (CAA) Job
- New Comparative Assessment With Annotation on Paragraphs (CAP) Job
- New Productivity Assessment (PA) job
- Additional Info Format
HEVAL Language pairs
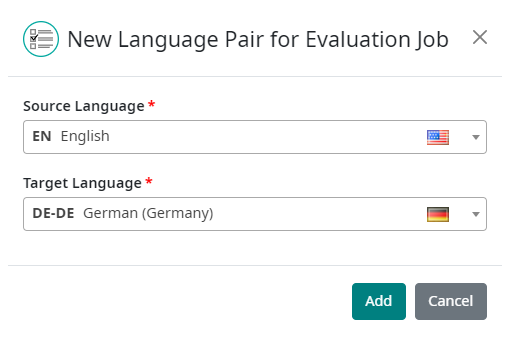
Each HEVAL job must have defined at least one language pair, on which
the evaluation is performed. Once the job has been created, language
pair can be added with ![]() button next to ‘Language Pairs’ title:
button next to ‘Language Pairs’ title:

When clicked, the modal dialog appears with ability to select source and target language:
Uploading files
Once the human evaluation job has been created and language pairs have been defined, the project manager must upload files for evaluation:
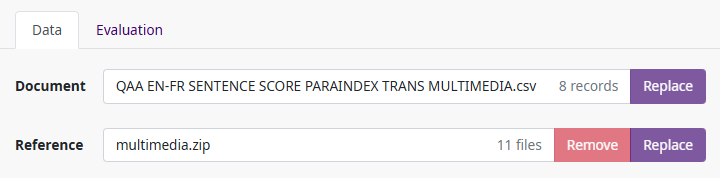
Evaluation data (mandatory) - The evaluation data must be provided in CSV format. The specific input data format requirements are described separately for each type of evaluation job in the sections above.
Reference material (optional) - The job creator can also upload a ZIP file containing reference material that is linked from the Additional Info field of the source CSV file. For more information about how to format Additional Info and link reference files, see Additional Info Format.
Note
The ZIP file must have a flat structure with no folders, and all files within it must have unique names.
Note
Both the evaluation data and reference ZIP file can be replaced until the first evaluator accepts the task. It is not allowed to change any data afterwards. Deletion of the reference files from Companion’s storage is possible using the Remove button.
HEVAL Job assignment workflow
Once a job has been created, the languages added, and files for evaluation uploaded, the project manager must invite evaluators to perform the evaluations. The invitation workflow works the same for all job types.
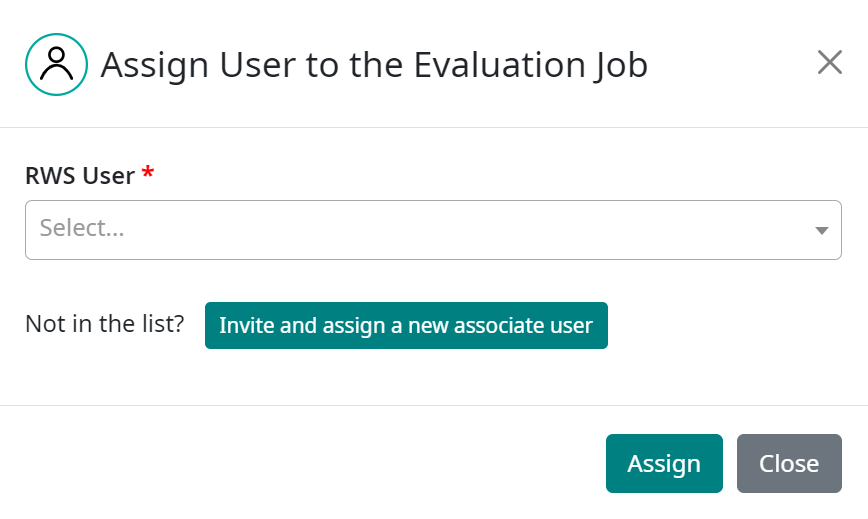
Select Evaluators.
Use the dropdown to select an existing user. If the selected user is an internal (RWS) user who has not yet logged on to Companion to perform work in the current workspace, they will receive an email notifying them that they have been added to the workspace in Companion. If the evaluator is not an existing user, you can:
Invite and assign a new user. New users will receive an invitation to register a new account in Companion. The new user will be added to the Companion user database only once they register their new account.
Note
List of users contains following user types:
 RWS users, already registered in Companion
RWS users, already registered in Companion Not yet registered RWS users (records from RWS Azure tenant)
Not yet registered RWS users (records from RWS Azure tenant) Associate users (registered in Companion)
Associate users (registered in Companion)
Each invited Evaluator will receive an email from Companion inviting them to perform a human evaluation job. The email will contain summary information about the job and will offer the invitee the possibility to Accept or Reject the assignment. Until the invitee responds, the job Status will remain PENDING.
If the user rejects the assignment, the job Status will be updated with REJECTED, and the project manager can delete the invitee and add a new Evaluator, as needed.
If the user accepts the assignment, the job Status will be updated with ACCEPTED, and the evaluator can proceed.
At any point during an active project, any user in the Workspace with the role of Maintainer or Owner can:
Cancel the job. When the job is canceled, the evaluator can be removed from the list and whatever work has been completed can be downloaded in a report.
Preview the evaluation job. The preview shows the job as it will be seen by the evaluator, but the evaluation features remain inactive.
View an evaluation. Individual evaluation results can be viewed in Companion for both completed and partially complete jobs.
Assign a new evaluator. Regardless of the number of minimum evaluators defined during set up, new evaluators can be added as needed.
Add a new language pair.
HEVAL Job review
PMs can analyze results of evaluated content (using downloaded Excel
reports) and decide if there are issues that must be fixed by
the linguist. In this case, PMs can share the issues with the linguist
and switch the status to In-Review using the  button
(‘Unlock for review’). The downloaded Excel reports contain deep links to
each of the evaluated segments, so if needed, the PM can send an extract of the Excel
report including the URLs of the segments that need to be fixed back to
the linguist.
button
(‘Unlock for review’). The downloaded Excel reports contain deep links to
each of the evaluated segments, so if needed, the PM can send an extract of the Excel
report including the URLs of the segments that need to be fixed back to
the linguist.
When the linguist is done with the review, they will mark the task as complete by
clicking the  button (‘Set as reviewed’). Once clicked, the task’s
status is changed to Reviewed.
button (‘Set as reviewed’). Once clicked, the task’s
status is changed to Reviewed.
Note
There might be several rounds of review, where the PM can change the status
directly from Reviewed to In-review using the button.
HEVAL Status overview
Here is the list of task statuses and their descriptions that you may see during the process of human evaluation. The task is an evaluation job for defined language pair, assigned to a linguist.
STATUS |
DESCRIPTION |
|---|---|
NEW (PENDING) |
Task has been created (Job is created with appropriate language pair and a linguist has been assigned to it). The Linguist receives a notification e-mail where the task can be either Accepted or Rejected. |
REJECTED |
Rejected task is not available for the linguist anymore, PM can still see it on the job list page with ability to remove it. |
ACCEPTED |
When the task is accepted, the evaluation can be executed by assigned linguist only. At this point, linguists can’t update already evaluated segments, while PMs can update them any time (except the task is in the final Validated status). |
CANCELLED |
PM can cancel tasks at any time. In such case, task disappears to assigned linguist and can’t be evaluated anymore. |
COMPLETED |
When all segments in the task are evaluated, its status is automatically changed to Completed. Based on evaluated content analysis (see HEVAL Job review) PMs can
switch to In-Review status using
|
IN-REVIEW |
In-review status enables updating of all segments in the task. Updates can be made only by the assigned linguist and performed as described and sent by PM (see HEVAL Job review). |
REVIEWED |
Reviewed status informs the PM that the task’s review is done and another round of content analysis can be performed. The PM decides (similarly to the Completed status) whether the task can be set to Validated, or another round of review is necessary. |
VALIDATED |
Final status, where further (mainly automated) processing of evaluation data is enabled. Note that the Validated status will disable the ability to review the task, but it can be un-validated (with the same button) at any time. |

The following chart outlines the status flow during the human evaluation process:

Automated Evaluation
Companion provides integration of human evaluation results with the computation of scoring metrics using the Automated Evaluation feature. Since two versions of text are required for comparison, automated evaluation is available only for CA, CAA, and PA job types:
CA type evaluations contain two comparable translations of the same source
PA type evaluations allow modification of the original text, where the changed text can be compared and evaluated against the original
Automated evaluation must be enabled for the job by checking the Allow Automated Evaluation checkbox during job creation.
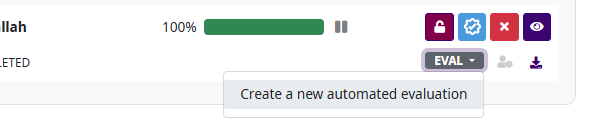
To calculate automated metrics, the job creator (or workspace owner) uses the EVAL dropdown menu attached to each language pair and user combination. The EVAL dropdown is gray when no evaluation has been performed and offers the option to create an automated evaluation. Once the evaluation is created, the EVAL dropdown changes color to red and contains several options:
View Analysis - Displays a complete analysis of all automated metrics calculated
View Segments - Displays all segments with highlighted changes and aggregated metrics per segment
Delete - Removes the automated evaluation
Note
EVAL dropdown is available only on 100% completed tasks (status COMPLETED, REVIEWED or VALIDATED).
Note
Creating an automated evaluation generates a new evaluation job in the Automated Evaluation section of Companion. The views accessible from Human Evaluation language pairs are links to the Automated Evaluation section.
HEVAL output reports
Human evaluation job results can be downloaded for individual evaluators
or for the whole language pair at any time by selecting the download icon
![]() .
.
The report is based on templates defined under Workspace Human Evaluation Report templates. In addition to the default empty template, users may create and upload their own template(s) for more efficient results processing.
In case there are multiple templates available, the following dialog is displayed allowing the user to select their preferred report template.
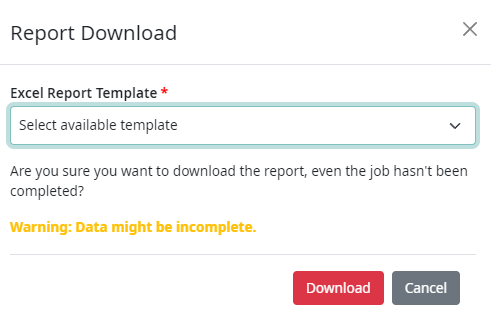
The results file name follows the convention:
{{Job name}}_{{srcLangCode}}_{{targetLangCode}}_report.xlsx
If the job is incomplete, the results file name will be appended with “_partial”.
Note
Job Feedback
Each report consists of tab(s) containing output data and Job Feedback tab, where you can find a general feedback, provided by a linguist, after job is done.