Companion Fundamentals
Companion offers four main features:
Each of these features is designed to be dynamic and extensible, offering users a high degree of customization. This document will act as a reference for Companion users, to help them get the most out of these features.
Working with MT and automated MT evaluation
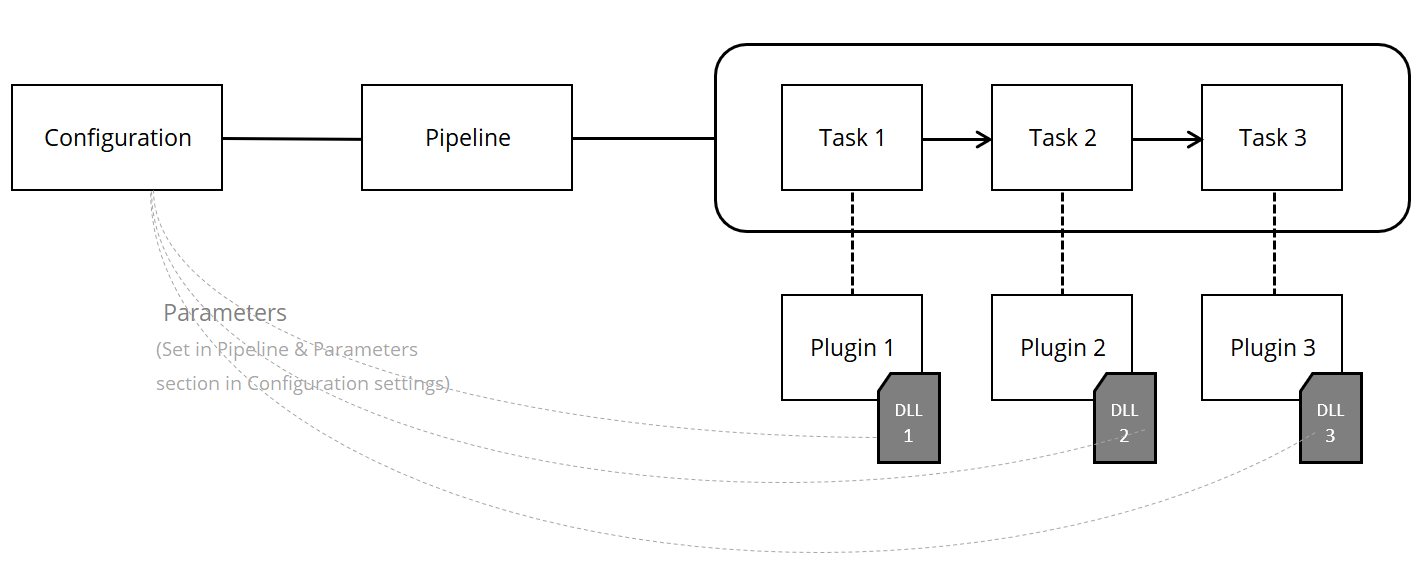
The MT and EVAL features are designed around a primary building block of the Configuration. Besides the standard metadata like Name, Alias and Description, each Configuration has an attached Pipeline, which describes a sequence of consecutive tasks that are executed when processing a Job in Companion. In Companion, a Job is defined as a unit of work containing text that is processed by Companion (for either machine translation or automated evaluation).
Each Pipeline also has standard metadata such as Name, Description, Format, Scope and Tasks. The most important aspect of the Pipeline is the sequence of Tasks it contains.
A Task in the Pipeline might have zero, one, or more parameters, depending on the purpose of the task. Task parameters in each Pipeline are stored in a Configuration.
Tasks vs. Plugins
In fact, the Task is a “materialized” Plugin, which is an executable code that performs a desired functionality. The number of parameters, their names and purpose are defined in the implementation of the Plugin.
Pipeline Formats
During job processing, data are exchanged between tasks in a pipeline in a pre-defined intermediate format that is specific to the type of job being processed. This format is standardized, so all tasks in the pipeline (read: all plugin implementations) are designed to work with it. At the beginning of the task execution, the plugin takes input data from the file and at the end, data are stored back to file in this format.
The following Pipeline Formats are used in Companion:
XLIFF: For all pipelines and tasks processing localization data, such as MT or another service which translates source text to target text.
RBX: Proprietary format used to store evaluation data.
At the beginning of each job execution, the input data (like string arrays, text files, TMX files, etc.) are converted to the appropriate Pipeline Format (XLIFF or RBX), depending on the specified configuration. (i.e., the Receiver)
At the end of the job execution, data are converted to the desired response format back from the pipeline format. (i.e., the Transmitter)
Aliases
Companion introduces Aliases for better identification of Configurations. An Alias is a textual identifier used mainly by the API, helping users to recognize Configurations in code easily and in a readable form.
Aliases are used in Workspaces and Configurations.
For workspaces, there is a rule that an Alias CANNOT be defined for two different Workspaces.
Configuration Aliases consist of two parts separated by an underscore (‘_’) character. The first part is the Alias of the Workspace where the Configuration lives, and the second part identifies the Configuration within the Workspace.
More than one configuration can share the same alias, but in this special case, the combination of language pairs defined in the configuration and its alias must be unique. This “special case” is applicable in the scenario where we have one set of language pairs in the same workspace using different settings (i.e., different MT engines) than another set. From the outside, API calls can be performed on both sets of languages with the same Configuration Alias.
Tip: Since the configuration alias is required to uniquely identify the specific configuration via the API, it is recommended to use alias names without any spaces; use underscores instead. Short aliases are also preferred.
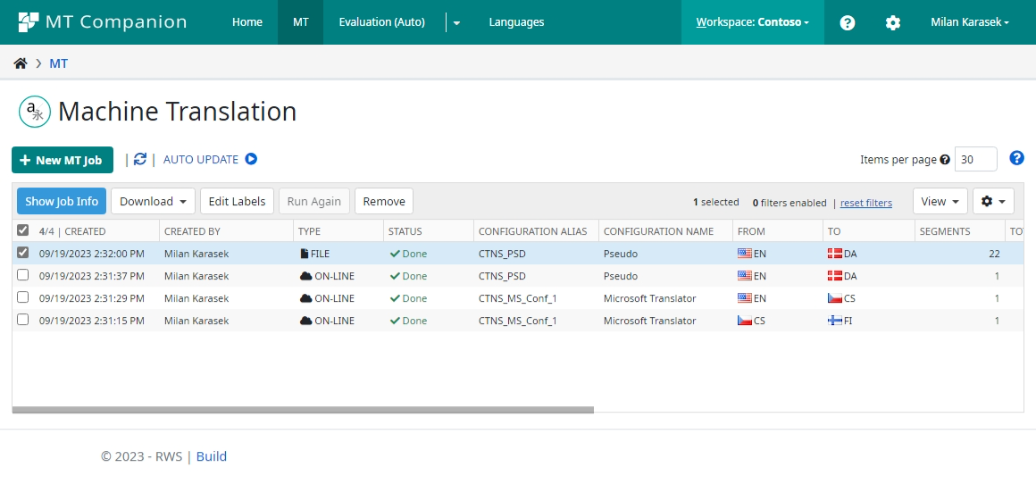
Job List Reference
Job lists are used on Machine Translation and Automated Evaluation pages in Companion. These job lists use a special web component that displays data in a grid, enabling users to conveniently filter and sort data.
Working with Human evaluation
HEVAL features are structured differently from MT and EVAL because they require participation from another type of user: the linguistic evaluator. Due to this fundamental difference, HEVAL offers tools that will allow an Companion user to initiate human evaluation tasks and collaborate with evaluators from inside or outside of RWS to perform the evaluation tasks.
Job Types
A human evaluation job must have a job type. The following types of evaluation have been defined.
JOB TYPE |
DESCRIPTION |
ACTIVITY |
GOAL |
|---|---|---|---|
Quality Assessment (QA) |
The evaluator is presented with up to 150 segments with aligned source and MT output. |
Score each segment on a scale defined by the selected scoring system. |
Evaluate the suitability of the MT output of a single model. |
Quality Assessment with Annotation (QAA) |
The evaluator is presented with up to 150 segments with aligned source and MT output. |
Score each segment on a scale defined by the selected scoring system. Annotate the source and MT output using the job specific Annotation Set. |
Evaluate the suitability of the MT output of a single model and annotate outputs to get more granular feedback. |
Quality Assessment with Annotation on Paragraphs (QAP) |
Based on QAA but operates on whole paragraphs. The first step is paragraph segmentation including segment alignment. The evaluator then scores and annotates each segment. |
Segment paragraphs, then score each segment on a scale defined by the selected scoring system. Annotate using the job specific Annotation Set. |
Evaluate the suitability of the MT output of a single model on paragraph context with annotation feedback. |
Comparative Assessment (CA) |
The evaluator is presented with up to 150 source segments aligned with MT output from two different MT engines. |
Score each MT output on a scale defined by the selected scoring system. |
Compare the MT output from two different engines to select the more suitable engine. |
Comparative Assessment with Annotation (CAA) |
The evaluator is presented with up to 150 source segments aligned with MT output from two different MT engines. |
Score each MT output on a scale defined by the selected scoring system. Annotate the Score and MT output using the job specific Annotation Set. |
Compare the MT output from two different engines to select the more suitable engine and annotate outputs to get more granular feedback. |
Comparative Assessment with Annotation on Paragraphs (CAP) |
Based on CAA but operates on whole paragraphs. The first step is paragraph segmentation including segment alignment. The evaluator then scores and annotates MT output from two different engines. |
Segment paragraphs, then score each MT output on a scale defined by the selected scoring system. Annotate using the job specific Annotation Set. |
Compare the MT output from two different engines on paragraph context and annotate outputs to get more granular feedback. |
Productivity Assessment (PA) |
The evaluator is presented with segments for translation from scratch and segments for post-editing. |
Translate or post-edit the segments as they are presented. |
Establish suitability of MTPE for a specific use case by evaluating productivity of post-editing versus translation from scratch. |
HEVAL Input File Naming Convention
To avoid errors in the HEVAL input file upload, the uploaded files must follow a specific naming convention, as follows:
{{Job type}}_{{Name}}_{{Source language code}}_{{Target language code}}.csv
Example:
DE_LanguageWeaverEvaluation_ENG_FRA.csv
Note that you can technically upload a file with any name. In case the name doesn’t follow the rule described above, user gets the warning message.
HEVAL Data Selection and Curation
Selecting data for human evaluation is a critical part of the human evaluation process. The selected segments should be representative of the content for which MT will be used in production. Moreover, human evaluation can be expensive, so curating a rich and representative data set can help to avoid issues that could eventually lead to rework or worse, inaccurate conclusions.
To that end, it is recommended that users of the Companion Human Evaluation features develop a robust process for selecting data for human evaluation. Such a process includes, but is not limited to:
including project linguists in data preparation
working with the customer to identify and collect the most appropriate content for evaluation
excluding duplicate and near duplicate segments (segments with high fuzzy overlap)
defining segment length requirements based on real production data
excluding garbage segments (i.e., corrupted characters, code, or URL-only segments)
including clean data that conforms to the format requirements defined for each job type
ensuring there are no gaps in the data
Scoring Systems
Scoring systems are specific to a job type. The user is prompted to select an appropriate scoring system when creating a new job. The user can develop their own scoring system, or they can use an existing scoring system that has been pre-defined in Companion.
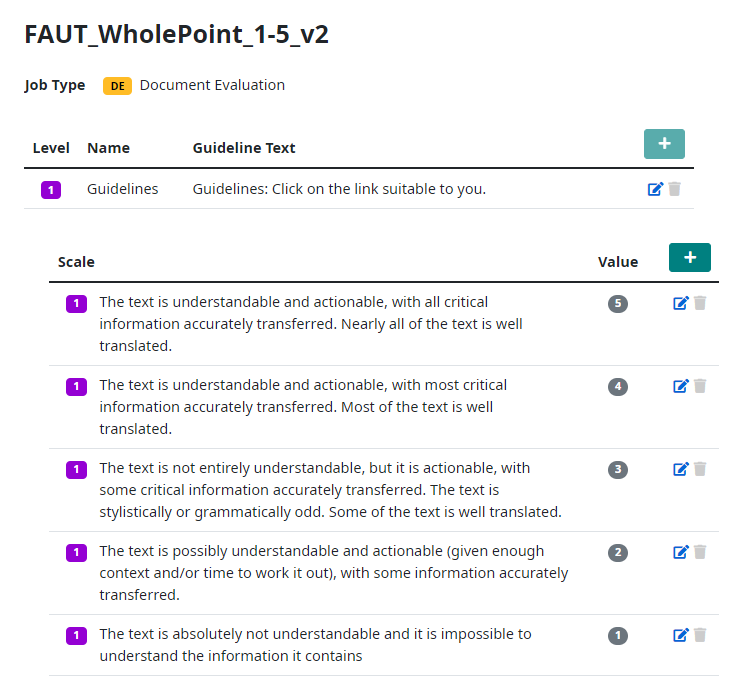
Companion allows users to create simple scoring systems as in the above single-level 5-point Likert scale, or more complex, multi-level scoring systems.
Annotation Sets
Human Evaluation Can be utilized not only for the purpose of the scoring quality, but also for the more granular criterions and levels, like linguistic, grammar etc. For this purpose Companion offers Annotation Set feature, allowing to create a set of annotation fields. The fields are defined separately for source and each translation.
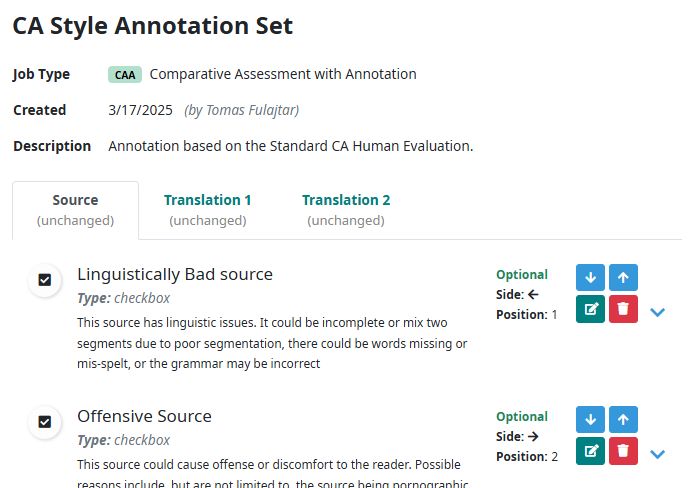
When the Annotation Set is assigned to a job, the annotation fields are displayed on the Evaluation Execution screen, allowing users to provide annotation feedback. See the example with the annotation fields highlighted in yellow.
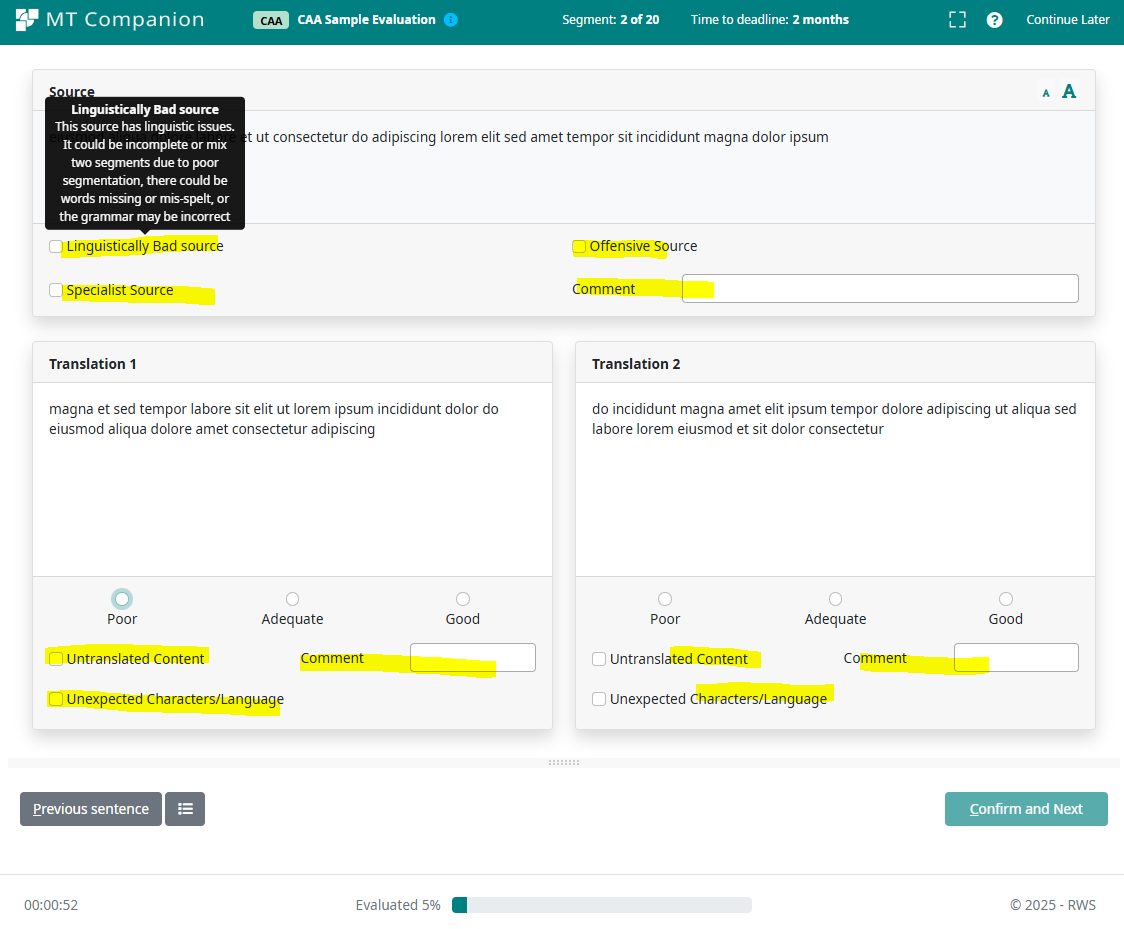
For more details on configuring annotation sets, see the Annotation Sets Management settings page.
Span Annotation Sets
In addition to standard Annotation Set fields that apply to an entire segment, Companion supports Span Annotation Sets — a specialised type of annotation that allows evaluators to select substrings (spans) within the source, translation 1, or translation 2 text and annotate them individually.
This is useful for fine-grained linguistic analysis, such as marking specific words or phrases that contain translation errors, terminology issues, or other quality-relevant observations.
When assigned to a job, the evaluator can highlight a portion of text on the evaluation form and apply the annotation fields defined in the set to that selected span.
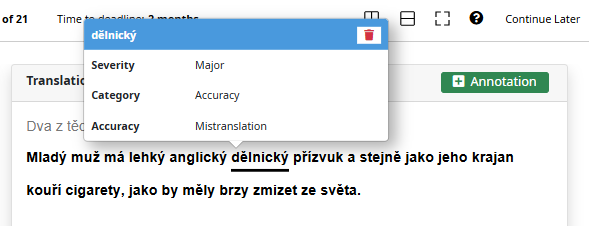
A Span Annotation Set is created in the same way as a regular Annotation Set, with the Span Annotation option enabled during Annotation Set Creation/Update.
For more details on configuring span annotation sets, see the Annotation Sets Management settings page.